


"We must try to lower costs by creating tools for translators"
- He is a professor at the Department of Systems Engineering and Automation at the UPV/EHU San Sebastian campus. In Leioa, researcher in the Department of Electrical and Electronics. He is surprised that the journalist has asked him about his thesis. He has been approached from the media before and this interest has been strange to him.


In addition to statistics, there are other translation methods that are often confused.
Yes, that is the current trend.
But you've chosen statistics.
Oh, yeah, yeah. The Ametzagaiña Group was working with translation memories and wanted to include statistics in the project. They helped us to identify translation units – such as name syntagms.
So you've confused the linguistic part with the statistical part.
We wanted to identify the translation units, but through linguistic methods. The subject, verb and other elements of the phrase can be identified by statistical methods. However, the statistical methods make this division using their own logic: I think this is how far the division is. Okay, but we wanted the partitioning to be done using linguistic methods, which is to segment the units using linguistic methods.
And for this you used the sample of weather forecasts of Euskalmet.
“The sky will be very cloudy in the afternoon on the coast and in the mountains...”. We took samples like this. The application for a limited field is what I have worked on, and the goal is to gradually increase the scope of application. But, this is just the beginning.
That's what I wanted to ask you. Sometimes it seems that machine translation is invented, for example because of the way the media narrates.
... it is clear that no, otherwise we would all use it on mobile! No, it's not invented.
How do you convey the work you do, how far have you come, for example?
We have been working on automatic statistical translation for a long time. In the 1990s, a group of IBM was formed in the United States, which turned the previous methods around. Twenty years have passed and we have not been able to translate naturally and correctly from one language to another. We are slowly combining linguistic and statistical methods.
Do they work in the same way with other languages?
After all, the knowledge of artificial intelligence is applied, it is the general methods that are applied for a specific problem. Our problem is quite salty because it is not mathematics, it is language, very rich.
You turn him around, you say he's rich instead of saying that language is a problem.
The challenge is to see what I can bring to linguistics through my methods.
Can you imagine when we will have the “perfect” translation?
I wouldn’t know how to predict, for example, that in so many years we will have a mid-level translator... Google has its own, it’s pretty good, but is it applicable to all areas? Not yet. Not yet. However, the evolution of science is very fast. There was a time when, in five or six years, no one oppressed your thesis, today your subject has become obsolete in a couple of years, a lot of people are working on it.
People expect to find the perfect translator on the Internet, for example.
Yeah, and then you're gonna try and do it wrong, right? What is mentioned in the congresses-and it is: what do you prefer, that the washing machine manual purchased from Taiwan is in perfect Taiwanese or in simple Basque? I prefer to be in the language I know, even if there is a mistake I prefer to understand it, than to be perfect in another language. The need for translators is very high. We must try to reduce costs by creating tools that help translators.
It's just as helpful.
We had a sample of Euskalmet in Basque and Spanish, but we needed something in English to publish it. The translator we hired charged us a million pesetas to translate 14,000 sentences, not much. Our system, when trained, took a few seconds to correct 1,500 sentences. I passed the sentences to the translator and said, “The work you’ve done has been done by me for a few seconds.” Of course, the machine didn't do as well as he did, but I told him to look at the quality. He was petrified, saying, “They’re not right, but they’re understandable.” It should be recognized that translating 1,500 sentences in a few seconds is fine. Then it will be less difficult for the translator to tell if he is right or wrong than to start translating from scratch.
Automatic translations require large volumes of corpus and the Basque language does not, nor do we share the translation memories that we have. Am I doing well?
Where do I get the samples? What is published in Basque, free of charge, easy and in a format that is convenient... the condition is too strong, it is difficult.
You contacted a thesis firm. Is it common here for the academic field and the company to collaborate?
They are quite divided. At university, we sometimes don’t know how to put the problems solved into practice. Then there’s the business world to put us in our place, “that’s useless, this is what society needs today.” There are very few theses related to the company. In the university we forget about the needs of society, companies are once again located on the ground. Our project was created at the request of a company.
The Basque language is much more difficult to translate because of its linguistic peculiarities, or this is not true and the problem is the lack of corpus.
On the one hand, Basque is very curious morphologically, it places suffixes one after the other and the meaning of the word changes a lot. On the other hand, the syntax is also very curious, what is done in Spanish is the subject, the verb and the components. In Basque the usual structure is the subject, the components and the verb, and the most important before the verb. When we are going to do translation, we must consider two things: one, to transfer the meaning from one to another, and the other, to then choose the correct order of words. The order between Catalan and Spanish is quite similar, the system does not have much trouble understanding this order, but for statistical systems it is a christ to work with remote alignments [such as Basque and Spanish]. The challenge is to make a translation between different languages.
English and other languages are in a similar situation, right?
Although Basque has few linguistic resources, it has few speakers. Trying to get things of the same quality with few resources is another challenge.
In other words, the Basque language is a pair of Finnish in singularities, but in number the Finnish language beats it.
Of course, of course. What they are saying now at the conferences is that we need special methods to promote restricted languages.
I've been to Singapore recently. Some parts of the newspapers were in Chinese and others in English. If you want to do the translation there you don’t have a parallel corpus, that is, this is the translation of this. It is the case of the newspaper Gara.
The challenge is to find content that has a great approximation in both languages.








Okzitaniako Tolosako elkartea da aipatu kolektiboa eta Frantziako Gobernuak dekretuz desegin zuen 2022an. Orain Estatu Kontseilua gobernuaren erabakia egokia dela berretsi du.
Sare Herritarrak antolatuta, pasa den urtarrilaren 11n Bilboko kaleak bete zituen manifestazio jendetsuaren ondoren, berriz sortu da eztabaida, euskal presoei salbuespen legeriarik aplikatzen ote zaion. Gure iritzia azaltzen saiatuko gara.
Espetxe politikan aldaketa nabarmena... [+]
Duela gutxi think tank izateko jaioa omen den Zedarriak bere 6. txostena aurkeztu zuen. Beren web orrialdean azaltzen dutenaren arabera, zedarriak ebidentea ez den bidea topatzeko erreferentziak dira. Hots, hiru probintzietako jendarteari bidea markatzeko ekimena. Agerraldi... [+]

Eskoziako Lur Garaietara otsoak itzularazteak basoak bere onera ekartzen lagunduko lukeela adierazi dute Leeds unibertsitateko ikertzaileek.. Horrek, era berean, klima-larrialdiari aurre egiteko balioko lukeela baieztatu dute, basoek atmosferako karbono-dioxidoa xurgatuko... [+]
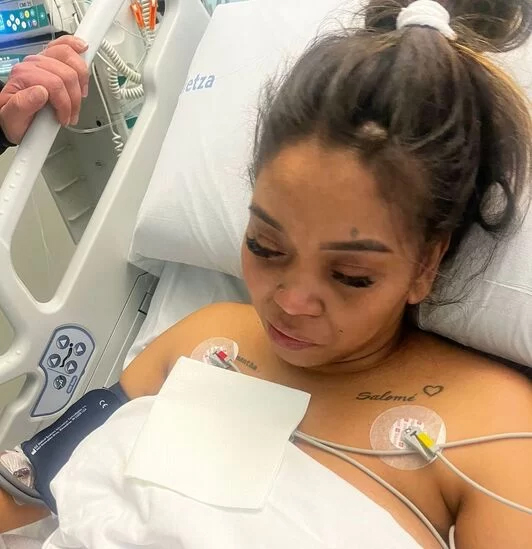
Karen Daniela Ágredok dioenez, atxilotu zutenean berak ez zuen ertzainik zauritu, haiek lurrera bota zuten eta konortea galdu zuen. Ondoren, Ertzaintzaren komisariaren zoruan iratzartu zen eta handik ospitalera eraman zuten.

Hiuzz + Bloñ + Adur
Noiz: otsailaren 15ean.
Non: Iruñeko Aitzina tabernan (Egun Motelak kolektiboa).
--------------------------------------------
Larunbat goiza Iruñean. Neguko eguzkitan lanera doazen gizon –eta ez gizon– bakarti batzuk... [+]
.jpg)


Zubiak eraiki Xiberoa eta Boliviaren artean. Badu jadanik 16 urte Boliviaren aldeko elkartea sortu zela Xiberoan. Azken urteetan, La Paz hiriko El Alto auzoko eskola bat, emazteen etxe baten sortzea, dendarien dinamikak edota tokiko irrati bat sustengatu dituzte.


11 doctors in health care earn 230,000 euros each year, one of the practices 18,000 euros
This Thursday, EH Bila asked the Government of Navarre to investigate and correct this situation in the plenary session of the Parliament of Navarre. The UPN and the PP have joined the... [+]
